1 Hive 数据类型
Hive 提供了基本数据类型和复杂数据类型,复杂数据类型是 Java 语言所不具有的。
1.1 基本数据类型
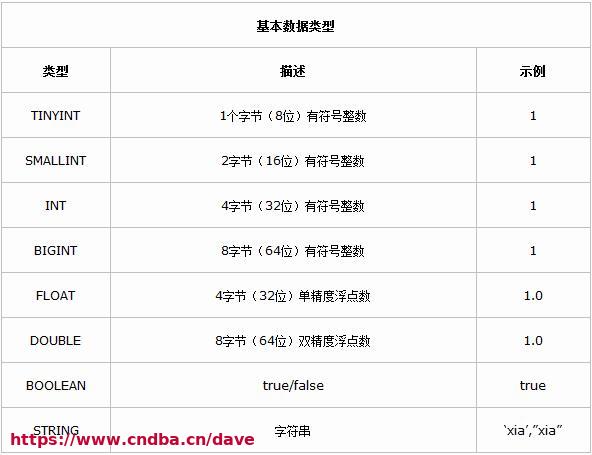
由上表我们看到hive不支持日期类型,在hive里日期都是用字符串来表示的,而常用的日期格式转化操作则是通过自定义函数进行操作。
hive是用java开发的,hive里的基本数据类型和java的基本数据类型也是一一对应的,除了string类型。有符号的整数类型:TINYINT、SMALLINT、INT和BIGINT分别等价于java的byte、short、int和long原子类型,它们分别为1字节、2字节、4字节和8字节有符号整数。
Hive的浮点数据类型FLOAT和DOUBLE,对应于java的基本类型float和double类型。而hive的BOOLEAN类型相当于java的基本数据类型boolean。
对于hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
1.2 复杂数据类型
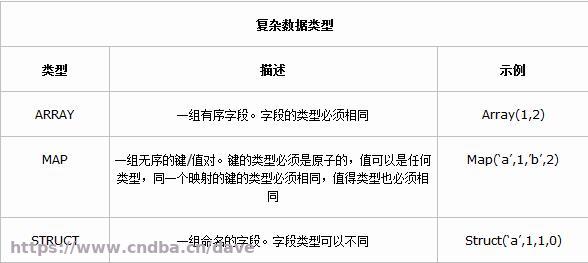
Hive 有三种复杂数据类型 ARRAY、MAP 和 STRUCT。ARRAY 和 MAP 与 Java 中的 Array 和 Map 类似,而STRUCT 与 C语言中的 Struct 类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。
复杂数据类型的声明必须使用尖括号指明其中数据字段的类型。定义三列,每列对应一种复杂的数据类型,如下所示。
CREATE TABLE complex(
col1 ARRAY< INT>,
col2 MAP< STRING,INT>,
col3 STRUCT< a:STRING,b:INT,c:DOUBLE>
)
1.3 类型转化
Hive 的原子数据类型是可以进行隐式转换的,类似于 Java 的类型转换,例如某表达式使用 INT 类型,TINYINT 会自动转换为 INT 类型, 但是 Hive 不会进行反向转化,例如,某表达式使用 TINYINT 类型,INT 不会自动转换为 TINYINT 类型,它会返回错误,除非使用 CAST 操作。
1)隐式类型转换规则如下。
1. 任何整数类型都可以隐式地转换为一个范围更广的类型,如 TINYINT 可以转换成 INT,INT 可以转换成 BIGINT。
2. 所有整数类型、FLOAT 和 String 类型都可以隐式地转换成 DOUBLE。
3. TINYINT、SMALLINT、INT 都可以转换为 FLOAT。
4.BOOLEAN 类型不可以转换为任何其它的类型。
2)可以使用 CAST 操作显示进行数据类型转换,例如 CAST(‘1’ AS INT) 将把字符串’1’ 转换成整数 1;如果强制类型转换失败,如执行 CAST(‘X’ AS INT),表达式返回空值 NULL。
2 Hive 文件格式
Hive文件存储格式包括以下几类:
1、TEXTFILE
2、SEQUENCEFILE
3、RCFILE
4、ORCFILE(0.11以后出现)
其中TEXTFILE为默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理。
SEQUENCEFILE,RCFILE,ORCFILE格式的表不能直接从本地文件导入数据,数据要先导入到textfile格式的表中,然后再从表中用insert导入SequenceFile,RCFile,ORCFile表中。
2.1 TEXTFILE 格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分, 从而无法对数据进行并行操作。
示例:
create table if not exists textfile_table(
site string,
url string,
pv bigint,
label string)
row format delimited
fields terminated by '/t'
stored as textfile;
插入数据操作:
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
insert overwrite table textfile_table select * from textfile_table;
2.2 SEQUENCEFILE 格式
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。 SequenceFile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,一般建议使用BLOCK压缩。
示例:
create table if not exists seqfile_table(
site string,
url string,
pv bigint,
label string)
row format delimited
fields terminated by '/t'
stored as sequencefile;
插入数据操作:
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
SET mapred.output.compression.type=BLOCK;
insert overwrite table seqfile_table select * from textfile_table;
2.3 RCFILE 文件格式
RCFILE是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
RCFILE文件示例:
create table if not exists rcfile_table(
site string,
url string,
pv bigint,
label string)
row format delimited
fields terminated by '/t'
stored as rcfile;
插入数据操作:
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
insert overwrite table rcfile_table select * from textfile_table;
2.4 TEXTFILE、SEQUENCEFILE、RCFILE三种文件的存储情况:
[hadoop@djt01 ~]$ hadoop dfs -dus /user/hive/warehouse/*
hdfs://hadoop@djt01:19000/user/hive/warehouse/hbase_table_1 0
hdfs://hadoop@djt01:19000/user/hive/warehouse/hbase_table_2 0
hdfs://hadoop@djt01:19000/user/hive/warehouse/orcfile_table 0
hdfs://hadoop@djt01:19000/user/hive/warehouse/rcfile_table 102638073
hdfs://hadoop@djt01:19000/user/hive/warehouse/seqfile_table 112497695
hdfs://hadoop@djt01:19000/user/hive/warehouse/testfile_table 536799616
hdfs://hadoop@djt01:19000/user/hive/warehouse/textfile_table 107308067
[hadoop@djt01 ~]$ hadoop dfs -ls /user/hive/warehouse/*/
-rw-r--r-- 2 hadoop supergroup 51328177 2014-03-20 00:42 /user/hive/warehouse/rcfile_table/000000_0
-rw-r--r-- 2 hadoop supergroup 51309896 2014-03-20 00:43 /user/hive/warehouse/rcfile_table/000001_0
-rw-r--r-- 2 hadoop supergroup 56263711 2014-03-20 01:20 /user/hive/warehouse/seqfile_table/000000_0
-rw-r--r-- 2 hadoop supergroup 56233984 2014-03-20 01:21 /user/hive/warehouse/seqfile_table/000001_0
-rw-r--r-- 2 hadoop supergroup 536799616 2014-03-19 23:15 /user/hive/warehouse/testfile_table/weibo.txt
-rw-r--r-- 2 hadoop supergroup 53659758 2014-03-19 23:24 /user/hive/warehouse/textfile_table/000000_0.gz
-rw-r--r-- 2 hadoop supergroup 53648309 2014-03-19 23:26 /user/hive/warehouse/textfile_table/000001_1.gz
总结: 相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE相比其余两种格式具有较明显的优势。
3 Hive 的数据存储
Hive的存储结构包括数据库、表、视图、分区和表数据等。数据库,表,分区等等都对应HDFS上的一个目录。表数据对应HDFS对应目录下的文件。
Hive中所有的数据都存储在HDFS中,没有专门的数据存储格式,因为Hive是读模式(Schema On Read),可支持TextFile,SequenceFile,RCFile 或者自定义格式等。
只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
- Hive 的默认列分隔符:控制符 Ctrl + A,/x01
- Hive 的默认行分隔符:换行符 /n
Hive中包含以下数据模型:
1) database:在 HDFS 中表现为${hive.metastore.warehouse.dir}目录下一个文件夹。
2) table:在 HDFS 中表现所属 database 目录下一个文件夹。
3) external table:与 table 类似,不过其数据存放位置可以指定任意 HDFS 目录路径。
4) partition:在 HDFS 中表现为 table 目录下的子目录。
5) bucket:在 HDFS 中表现为同一个表目录或者分区目录下根据某个字段的值进行 hash 散列之后的多个文件。
6) view:与传统数据库类似,只读,基于基本表创建。
Hive的元数据存储在 RDBMS 中,除元数据外的其它所有数据都基于 HDFS 存储。默认情况下,Hive 元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的测试。实际生产环境中不适用,为了支持多用户会话,则需要一个独立的元数据库,使用MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
Hive中的表分为内部表、外部表、分区表和分桶表。
内部表和外部表的区别:
- 删除内部表,删除表元数据和数据
- 删除外部表,删除元数据,不删除数据
内部表和外部表的使用选择:
大多数情况,他们的区别不明显,如果数据的所有处理都在 Hive 中进行,那么倾向于选择内部表,但是如果 Hive 和其他工具要针对相同的数据集进行处理,外部表更合适。
使用外部表访问存储在 HDFS 上的初始数据,然后通过 Hive 转换数据并存到内部表中。使用外部表的场景是针对一个数据集有多个不同的 Schema。
通过外部表和内部表的区别和使用选择的对比可以看出来,hive 其实仅仅只是对存储在HDFS 上的数据提供了一种新的抽象。而不是管理存储在 HDFS 上的数据。所以不管创建内部表还是外部表,都可以对 hive 表的数据存储目录中的数据进行增删操作。
分区表和分桶表的区别:
Hive 数据表可以根据某些字段进行分区操作,细化数据管理,可以让部分查询更快。同时表和分区也可以进一步被划分为 Buckets,分桶表的原理和 MapReduce 编程中的HashPartitioner 的原理类似分区和分桶都是细化数据管理,但是分区表是手动添加区分,由于 Hive 是读模式,所以对添加进分区的数据不做模式校验,分桶表中的数据是按照某些分桶字段进行 hash 散列形成的多个文件,所以数据的准确性也高很多。





