1 查看表中系统列
PG 每张表中有几个系统隐含列,这些系统列字段在psql使用“/d”命令中并不显示。因为表中已隐含了某些名字的字段,所以用户定义的字段名称不能再使用这些名字,这个限制与名字是否为关键字没有关系,即使字段名称用双引号括起来也不行。
PG 中pg_attribute 视图保存了所有表的列的信息,可以通过该视图查看有哪些系统字段。
cndba=# select version();
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 14.6 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44), 64-bit
(1 row)
这个是dave 表的列,有2个:
cndba=# /d dave
Table "public.dave"
Column | Type | Collation | Nullable | Default
--------+-----------------------+-----------+----------+---------
id | integer | | |
url | character varying(40) | | |
cndba=#
cndba=# select attname, attnum, atttypid::regtype from pg_attribute where attrelid = 'dave'::regclass;
attname | attnum | atttypid
----------+--------+-------------------
tableoid | -6 | oid
cmax | -5 | cid
xmax | -4 | xid
cmin | -3 | cid
xmin | -2 | xid
ctid | -1 | tid
id | 1 | integer
url | 2 | character varying
(8 rows)
cndba=#
通过查询,我们发现PostgreSQL 为我们增加了 6 个额外的系统字段,它们的 attnum 属性都是负数。
PostgreSQL 类型转换CAST / 双冒号(::) 说明
https://www.cndba.cn/dave/article/116402
官网对系统列的说明如下:
https://www.postgresql.org/docs/current/ddl-system-columns.html
这些系统字段如下:
- oid:行对象标识符(对象ID)。在PG 9中可以在创建表时使用了”with oids”或配置参数”default with oids”的值为真时才出现。在PG 14中已经不支持该语法。
- tableoid:包含本行的表的oid。对父表(该表存在有继承关系的子表)进行查询时,使用这个字段,就可以知道某一行来自父表还是子表,以及是哪个子表。tableoid可以和pg_class的oid字段连接起来获取表名字。
- xmin:插入该行版本的事务ID。
- xmax:删除此行时的事务ID,第一次插入时,此字段为0。如果查询出来此字段不为0,则可能是删除这行的事务还没有提交,或者是删除此行的事务回滚掉了。
- cmin:事务内部插入类操作的命令ID,此标识是从0开始的。
- cmax:事务内部删除类操作的命令ID,如果不是删除命令,此字段为0.
- ctid:一个行版本在它所处的表内的物理位置。类似于 Oracle 中的伪列 ROWID。
2 系统字段说明
2.1 OID
官方手册对OID的描述如下:
https://www.postgresql.org/docs/current/datatype-oid.html
Object identifiers (OIDs) are used internally by PostgreSQL as primary keys for various system tables. Type oid represents an object identifier. There are also several alias types for oid, each named regsomething. Table 8.26 shows an overview.
The oid type is currently implemented as an unsigned four-byte integer. Therefore, it is not large enough to provide database-wide uniqueness in large databases, or even in large individual tables.
The oid type itself has few operations beyond comparison. It can be cast to integer, however, and then manipulated using the standard integer operators. (Beware of possible signed-versus-unsigned confusion if you do this.)
The OID alias types have no operations of their own except for specialized input and output routines. These routines are able to accept and display symbolic names for system objects, rather than the raw numeric value that type oid would use. The alias types allow simplified lookup of OID values for objects.
在PostgreSQL内部使用对象标识符(oid)作为各种系统表的主键。系统不会给用户创建的表增加一个oid系统字段,oid字段生成的序列值是全局的。
在PG 9中还支持建表时使用”with oids”选项为表增加 oid字段,在PG 14中目前已经不支持该语法。
https://www.postgresql.org/docs/current/sql-createtable.html
creating a table WITH OIDS is not supported anymore.
oid类型代表一个对象标识符,oid还有几个表示具体对象类型的别名,都已reg开头,具体如下: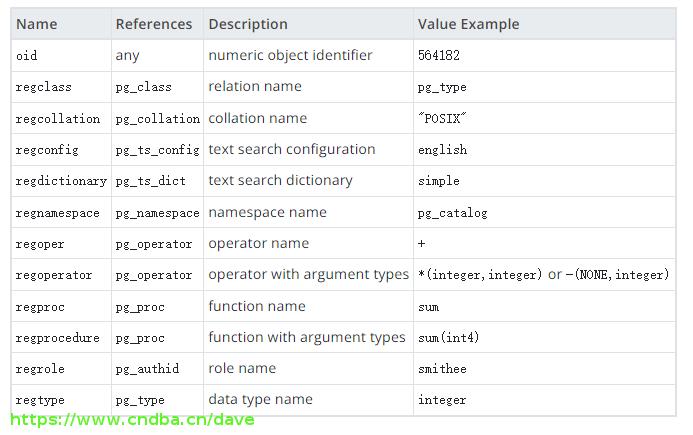
听过这些oid 别名的使用,可以不再需要额外关联其他的系统来查询相关对象信息,比如pg_type,pg_class。 我这里看一个regclass的数据类型,其数据来源pg_class 这个数据字典,对于pg中的对象来说,oid与表名存在对象关系,这个关系我们可以从pg_class中得到。
postgres=# select oid, relname from pg_class where relname = 'dave';
oid | relname
-------+---------
16418 | dave
(1 row)
因此通过regclass,我们就不需要在通过查询pg_class表来获取对象与oid的对应关系了。
示例:直接通过oid :: regclass 将oid 转换成表名:
postgres=# SELECT oid :: regclass AS table_name, relname FROM pg_class WHERE relkind = 'r';
table_name | relname
--------------------------------------------+-------------------------
dave | dave
ustc | ustc
pg_statistic | pg_statistic
pg_type | pg_type
pg_foreign_table | pg_foreign_table
pg_authid | pg_authid
pg_statistic_ext_data | pg_statistic_ext_data
示例2:将表名转换成oid:
postgres=# SELECT oid, relname FROM pg_class WHERE oid = 'dave'::regclass;
oid | relname
-------+---------
16418 | dave
(1 row)
2.2 TABLEOID
tableoid包含本行的表的oid。对父表(该表存在有继承关系的子表)进行查询时,使用这个字段,就可以知道某一行来自父表还是子表,以及是哪个子表。tableoid可以和pg_class的oid字段连接起来获取表名字。
postgres=# select tableoid,id,url from dave;
tableoid | id | url
----------+----+----------------------
16418 | 1 | https://www.cndba.cn
16418 | 2 | https://www.cndba.cn
(2 rows)
2.3 CTID
ctid表示数据行在它所处的表内的物理位置。ctid 字段的类型是tid。尽管ctid可以非常快速地定位数据行,但每次VACUUM FULL之后,数据行在块内的物理位置就会移动,即ctid 会发生变化,所以ctid是不能作为长期的行标识符的,应该使用主键来标识一个逻辑行。
查看ctid的示例如下:
postgres=# select ctid,id,url from dave;
ctid | id | url
-------+----+----------------------
(0,1) | 1 | https://www.cndba.cn
(0,2) | 2 | https://www.cndba.cn
(2 rows)
从查询结果可以看出ctid由两个数字组成,第一个数字表示物理块号,第二个数字表示在物理块中的行号。
ctid类型可以使用字符串输入:
postgres=# select ctid,id,url from dave where ctid='(0,2)';
ctid | id | url
-------+----+----------------------
(0,2) | 2 | https://www.cndba.cn
(1 row)
还可以利用ctid可以删除一个表中的重复记录。
查看表中数据:
postgres=# select * from dave;
id | url
----+----------------------
1 | https://www.cndba.cn
2 | https://www.cndba.cn
1 | https://www.cndba.cn
1 | https://www.cndba.cn
1 | https://www.cndba.cn
(5 rows)
postgres=#
删除表中重复数据:(SQL 逻辑是id值相等且ctid不等的即为重复数据)
postgres=# delete from dave a where a.ctid <>(select min(b.ctid) from dave b where a.id = b.id);
DELETE 3
postgres=# select ctid,id,url from dave;
ctid | id | url
-------+----+----------------------
(0,1) | 1 | https://www.cndba.cn
(0,2) | 2 | https://www.cndba.cn
(2 rows)
postgres=#
上例的SQL语句在表dave的记录比较多时,效率比较差,这时可以使用下面这个更高效的删除表中重复数据的 SQL:
delete
from
ustc
where
ctid = any(array(
select
ctid
from
(
select
row_number() over (partition by id),
ctid
from
ustc) x
where
x.row_number>1);
postgres=# select * from ustc;
id | url
----+----------------------
1 | https://www.cndba.cn
1 | https://www.cndba.cn
1 | https://www.cndba.cn
1 | https://www.cndba.cn
1 | https://www.cndba.cn
(5 rows)
postgres=# delete from ustc where ctid = any(array(select ctid from ( select row_number() over (partition by id), ctid from ustc) x where x.row_number>1);
postgres# ;
postgres# select * from ustc;
postgres#
2.4 XMIN、XMAX、CMIN、CMAX
这四个字段在多版本(MVCC)实现中用于控制数据行是否对用户可见。
2.4.1 XMIN/XMAX
PostgreSQL会将修改前后的数据都存储在相同的结构中,这又分为以下几种情况。
- 新插入一行时,将新插入行的xmin填写为当前的事务ID,xmax填0。
- 修改某一行时,实际上是新插入一行,旧行上的xmin不变,旧行上的xmax改为当前的事务ID,新行上的xmin填为当前事务ID,新行上的xmax填为0。
- 删除一行时,把被删除行上的xmax填为当前的事务ID。
根据上述描述,可以看出:xmin就是标记插入数据行的事务ID,而xmax就是标记删除数据行的事务ID。注意PG中没有修改数据行的操作,因为修改数据行实际上就是把旧数据行上的xmax标记为自己的事务ID(相当于打上删除标记),然后再新插入一条记录。
2.4.2 CMIN/CMAX
CMIN和CMAX用于判断同一个事务内的不同命令导致的行版本变化是否可见。
如果一个事务内的所有命令都是严格按顺序执行的,那么每个命令都能看到之前该事务内的所有变更,这种情况下不需要使用命令标识。
一般编程中,对一个数组和列表遍历时,是不允许在遍历中删除或增加元素的,因为这样会导致逻辑错误。而在数据库中,对游标进行遍历时,可以对游标引用的表进行插入或删除行的操作而不出现逻辑错误,这是因为游标是一个快照,遍历时的删除或增加操作不会影响游标的数据,遍历游标时看到的是声明游标时的数据快照而不是执行时的数据,所以它在扫描数据时,会忽略声明游标后对数据的变更,因为这些变更对该游标都是无效的。
游标后续看到的数据都是声明游标之前的一个快照,相当于游标与后续的命令并发交错执行,这与事务之间的交错执行类似,存在数据可见性的问题。
与解决事务内可见性问题类似,PostgreSQL引入了命令ID的概念。行上记录了操作这行的命令ID,当其他命令读取这行数据时,如果当前的命令ID大于等于数据行上的命令ID,说明这行数据是可见的;如果当前的命令ID小于数据行上的命令ID,则这条数据不可见。
命令ID的分配规则如下:
- 每个命令使用事务内一个全局命令标识计数器的当前值作为当前命令标识。
- 事务开始时,命令标识计数器被置为初值0。
- 执行更新性的命令(如 insert、update、delete、select …for update)时,在 SQL执行后命令标识计数器加1。
- 当命令标识计数器经过不断累加又回到初值0时,报错“cannot have more than 2^32-1 commands in a transaction”,即一个事务中命令的个数最多为2^32-1个。
版权声明:本文为博主原创文章,未经博主允许不得转载。






