1背景
yugong 是阿里巴巴推出的去Oracle数据迁移同步工具(全量+增量,目标支持MySQL/DRDS)
08年左右,阿里巴巴开始尝试MySQL的相关研究,并开发了基于MySQL分库分表技术的相关产品,Cobar/TDDL(目前为阿里云DRDS产品),解决了单机Oracle无法满足的扩展性问题,当时也掀起一股去IOE项目的浪潮,愚公这项目因此而诞生,其要解决的目标就是帮助用户完成从Oracle数据迁移到MySQL上,完成去IOE的第一步.
2项目介绍
整个数据迁移过程,分为两部分:
1.全量迁移
2.增量迁移
过程描述:
1.增量数据收集 (创建oracle表的增量物化视图)
2.进行全量复制
3.进行增量复制 (可并行进行数据校验)
4.原库停写,切到新库
3架构
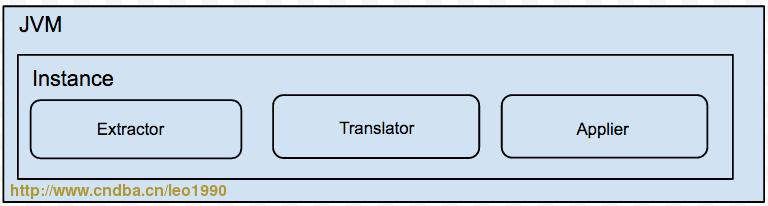
说明:
1.一个Jvm Container对应多个instance,每个instance对应于一张表的迁移任务
- instance分为三部分
a. extractor (从源数据库上提取数据,可分为全量/增量实现)
b. translator (将源库上的数据按照目标库的需求进行自定义转化)
c. applier (将数据更新到目标库,可分为全量/增量/对比的实现)4环境要求
4.1 操作系统
a. 纯java开发,有bat和shell脚本,windows/linux均可支持.
b. jdk建议使用1.6.25以上的版本,稳定可靠,目前阿里巴巴使用基本为此版本.4.2 数据库
a. 源库为oracle,目标库可为mysql/drds/oracle. 基于标准jdbc协议开发,对数据库暂无版本要求
需要的数据库账户权限: - 源库(oracle)
GRANT SELECT,INSERT,UPDATE,DELETE ON XXX TO XXX; #常见CRUD权限
GRANT CREATE ANY MATERIALIZED VIEW TO XXX;
GRANT DROP ANY MATERIALIZED VIEW TO XXX; - 目标库(mysql/oracle)
GRANT SELECT,INSERT,UPDATE,DELETE ON XXX TO XXX;5实验步骤
5.1 二进制下载地址:
https://github.com/alibaba/yugong/releases5.2 解压缩yugong二进制文件
在源端服务器安装即可 [root@www.cndba.cn /]# mkdir /yugong [root@www.cndba.cn software]# tar zxvf /software/yugong-1.0.3.tar.gz -C /yugong5.3 授权数据库账户权限
1)创建Oracle用户 本实例是创建yugong 用户可以访问要同步用户所有表的权限,也可不用创建yugong用户,在 配置文件里直接写要抽取数据的用户名。例如test 用户 CREATE USER yugong IDENTIFIED BY yugong; GRANT CONNECT,RESOURCE TO yugong; GRANT SELECT any table,INSERT any table,UPDATE any table,DELETE any table TO yugong; GRANT CREATE ANY MATERIALIZED VIEW TO yugong; GRANT DROP ANY MATERIALIZED VIEW TO yugong; 为了方便也可以直接赋值dba 权限 GRANT dba to yugong; 2)创建同步到mysql的数据库 create database test; grant all on test.* to 'yugong'@'%' identified by 'yugong'; flush privileges;5.4 在源库oracle上创建一张待同步表
create table oracle1 ( id NUMBER(11) , name varchar2(32) , alias_name char(32) default ' ' not null, amount number(11,2), score number(20), text_b blob, text_c clob, gmt_create date not null, gmt_modified date not null, CONSTRAINT oracle1_pk_id PRIMARY KEY (id) ); insert into oracle1 values(1,'ljh','agapple',10.2,100, NULL , NULL ,sysdate,sysdate); insert into oracle1 values(2,'yugong','yugong',16.88,2088, NULL , NULL ,sysdate,sysdate);5.5 在目标库MySQL上创建一张目标表
create table mysql1 ( id bigint(20) unsigned auto_increment, display_name varchar(128) , amount varchar(32), score bigint(20) unsigned , text_b blob, text_c text, gmt_create timestamp not null, gmt_modified timestamp not null, gmt_move timestamp not null, CONSTRAINT mysql1_pk_id PRIMARY KEY (id) );
5.6 修改配置文件yugong.properties
1.需要修改源和目标数据库的账号信息
2.需要修改yugong.table.white信息,登记需要同步的测试表
3.其他的可以使用默认值,关于配置参数详解,请参考:[https://github.com/alibaba/yugong/wiki/AdminGuide](https://github.com/alibaba/yugong/wiki/AdminGuide)
[root@www.cndba.cn conf]# cat yugong.properties
yugong.database.source.username=yugong
yugong.database.source.password=yugong
yugong.database.source.type=ORACLE
yugong.database.source.url=jdbc:oracle:thin:@192.168.1.69:1521/cndba
yugong.database.source.encode=UTF-8
yugong.database.source.poolSize=30
yugong.database.target.url=jdbc:mysql://192.168.1.77:3306/test
yugong.database.target.username=yugong
yugong.database.target.password=yugong
yugong.database.target.type=MYSQL
yugong.database.target.encode=UTF-8
yugong.database.target.poolSize=30
yugong.table.batchApply=true
yugong.table.onceCrawNum=1000
yugong.table.tpsLimit=0
# use connection default schema
yugong.table.ignoreSchema=false
# skip Applier Load Db failed data
yugong.table.skipApplierException=false
#yugong.table.white=yugong_example_join,oracle1,yugong_example_two
yugong.table.white= oracle1
yugong.table.black=
# tables use multi-thread enable or disable
yugong.table.concurrent.enable=true
# tables use multi-thread size
yugong.table.concurrent.size=5
# retry times
yugong.table.retry.times = 3
# retry interval or sleep time (ms)
yugong.table.retry.interval = 1000
# MARK/FULL/INC/ALL(REC+FULL+INC)/CHECK/CLEAR
yugong.table.mode=ALL
# yugong extractor
yugong.extractor.dump=false
yugong.extractor.concurrent.enable=true
yugong.extractor.concurrent.global=false
yugong.extractor.concurrent.size=30
yugong.extractor.noupdate.sleep=1000
yugong.extractor.noupdate.thresold=0
yugong.extractor.once=false
# {0} is all columns , {1}.{2} is schemaName.tableName , {3} is primaryKey
#yugong.extractor.sql=select /*+parallel(t)*/ {0} from {1}.{2} t
#yugong.extractor.sql=select * from (select {0} from {1}.{2} t where {3} > ? order by {3} asc) where rownum <= ?
# yugong applier
yugong.applier.concurrent.enable=true
yugong.applier.concurrent.global=false
yugong.applier.concurrent.size=30
yugong.applier.dump=false
# stats
yugong.stat.print.interval=5
yugong.progress.print.interval=1
# alarm email
yugong.alarm.email.host = smtp.163.com
yugong.alarm.email.username = test@163.com
yugong.alarm.email.password =
yugong.alarm.email.stmp.port = 465
yugong.alarm.receiver=test@163.com
5.7 配置对应的DataTranslator
如果要迁移的oracle和mysql的表结构不同,比如表名,字段名有差异,字段类型不兼容,需要使用自定义数据转换。如果完全相同那就可以跳过此章节
整个数据流为:DB -> Extractor -> DataTranslator -> Applier -> DB,本程序预留DataTranslator接口,允许外部用户自定义数据处理逻辑,比如:
1.表名不同
2.字段名不同
3.字段类型不同
4.字段个数不同
5.运行过程join其他表的数据做计算等
几点说明:
1.DataTranslator目前仅支持java扩展,允许用户完成类实现后,将类源文件放置到conf/translator/目录下,yugong启动后会进行动态编译.
2.DataTranslator目前查找规则会根据表名自动查找,比如需要处理的表为otter2.test_all_one_pk,查找的时候会将test_all_one_pk转化为TestAllOnePk + 固定DataTranslator后缀. (如果当前classpath中存在,优先使用classpath,如果不存在,则到conf/translator中查找该名字的java文件进行动态编译)
3.目前提供了几个样例,可参见解压后的conf/translator/目录
a. YugongExampleOracleDataTranslator (当前例子,介绍oracle一张表和mysql一张表之间的转换处理)
b. YugongExampleJoinDataTranslator (介绍oracle多张表和mysql一张表之间的转换处理,oracle中会通过一张表为主表,运行时join查询出其他表数据,合并同步到mysql)
c. YugongExampleTwoDataTranslator (介绍oracle一张表和mysql多张表之间的转换处理,oracle的一张大表数据,可运行时拆分后输出到多张mysql表上)
根据DataTranslator目前查找规则会根据表名自动查找
#源库oracle的表为mysql1,故对应conf/translator/ YugongExampleOracleDataTranslator.java
自定义转换逻辑
* 例子包含特性:
* 1. schema/table名不同. oracle中为oracle1,mysql中为test.mysql1
* 2. 字段名字不同. oracle中的name字段,映射到mysql的display_name
* 3. 字段逻辑处理. mysql的display_name字段数据来源为oracle库的:name+'('alias_name+')'
* 4. 字段类型不同. oracle中的amount为number类型,映射到mysql的amount为varchar文本型
* 5. 源库多一个字段. oracle中多了一个alias_name字段
* 6. 目标库多了一个字段. mysql中多了一个gmt_move字段,(简单的用迁移时的当前时间进行填充)
[root@www.cndba.cn translator]# vi YugongExampleOracleDataTranslator.java
package com.taobao.yugong.translator;
import java.sql.Types;
import java.util.Date;
import org.apache.commons.lang.ObjectUtils;
import com.taobao.yugong.common.db.meta.ColumnMeta;
import com.taobao.yugong.common.db.meta.ColumnValue;
import com.taobao.yugong.common.model.record.Record;
/**
* 一个迁移的例子,涵盖一些基本转换操作
*
* <pre>
* 例子包含特性:
* 1. schema/table名不同. oracle中为oracle1,mysql中为test.mysql1
* 2. 字段名字不同. oracle中的name字段,映射到mysql的display_name
* 3. 字段逻辑处理. mysql的display_name字段数据来源为oracle库的:name+'('alias_name+')'
* 4. 字段类型不同. oracle中的amount为number类型,映射到mysql的amount为varchar文本型
* 5. 源库多一个字段. oracle中多了一个alias_name字段
* 6. 目标库多了一个字段. mysql中多了一个gmt_move字段,(简单的用迁移时的当前时间进行填充)
*
* 测试的表结构:
* // oracle表
* create table oracle1
* (
* id NUMBER(11) ,
* name varchar2(32) ,
* alias_name char(32) default ' ' not null,
* amount number(11,2),
* score number(20),
* text_b blob,
* text_c clob,
* gmt_create date not null,
* gmt_modified date not null,
* CONSTRAINT oracle1_pk_id PRIMARY KEY (id)
* );
*
* // mysql表
* create table test.mysql1
* (
* id bigint(20) unsigned auto_increment,
* display_name varchar(128) ,
* amount varchar(32),
* score bigint(20) unsigned ,
* text_b blob,
* text_c text,
* gmt_create timestamp not null,
* gmt_modified timestamp not null,
* gmt_move timestamp not null,
* CONSTRAINT mysql1_pk_id PRIMARY KEY (id)
* );
* </pre>
*
* @author agapple 2013-10-10 下午3:28:33
*/
public class YugongExampleOracleDataTranslator extends AbstractDataTranslator implements DataTranslator {
public boolean translator(Record record) {
// 1. schema/table名不同
// record.setSchemaName("test");
record.setTableName("mysql1");
// 2. 字段名字不同
ColumnValue nameColumn = record.getColumnByName("name");
if (nameColumn != null) {
nameColumn.getColumn().setName("display_name");
}
// 3. 字段逻辑处理
ColumnValue aliasNameColumn = record.getColumnByName("alias_name");
if (aliasNameColumn != null) {
StringBuilder displayNameValue = new StringBuilder(64);
displayNameValue.append(ObjectUtils.toString(nameColumn.getValue()))
.append('(')
.append(ObjectUtils.toString(aliasNameColumn.getValue()))
.append(')');
nameColumn.setValue(displayNameValue.toString());
}
// 4. 字段类型不同
ColumnValue amountColumn = record.getColumnByName("amount");
if (amountColumn != null) {
amountColumn.getColumn().setType(Types.VARCHAR);
amountColumn.setValue(ObjectUtils.toString(amountColumn.getValue()));
}
// 5. 源库多一个字段
record.removeColumnByName("alias_name");
// 6. 目标库多了一个字段
ColumnMeta gmtMoveMeta = new ColumnMeta("gmt_move", Types.TIMESTAMP);
ColumnValue gmtMoveColumn = new ColumnValue(gmtMoveMeta, new Date());
gmtMoveColumn.setCheck(false);// 该字段不做对比
record.addColumn(gmtMoveColumn);
// ColumnValue text_c = record.getColumnByName("text_c");
// try {
// text_c.setValue(new String((byte[]) text_c.getValue(), "GBK"));
// } catch (UnsupportedEncodingException e) {
// e.printStackTrace();
// }
return super.translator(record);
}
}
注意:一定要配置DataTranslator,否则yugong 进程无法启动,即使要同步的表名一样。
5.8 启动yugong进程
[root@www.cndba.cn bin]# cd /yugong/bin/
./startup.sh
5.9 查看日志
查看总日志
[root@www.cndba.cn yugong]# cd /yugong/logs/yugong
[root@www.cndba.cn yugong]# tail -50f table.log
2018-04-23 15:12:20.132 [main] INFO com.taobao.yugong.YuGongLauncher - ## start the YuGong.
2018-04-23 15:12:20.258 [main] INFO com.taobao.yugong.controller.YuGongController - check source database connection ...
2018-04-23 15:12:20.304 [main] INFO com.taobao.yugong.controller.YuGongController - check source database is ok
2018-04-23 15:12:20.306 [main] INFO com.taobao.yugong.controller.YuGongController - check target database connection ...
2018-04-23 15:12:20.336 [main] INFO com.taobao.yugong.controller.YuGongController - check target database is ok
2018-04-23 15:12:20.337 [main] INFO com.taobao.yugong.controller.YuGongController - check source tables read privileges ...
2018-04-23 15:12:20.417 [main] INFO com.alibaba.druid.pool.DruidDataSource - {dataSource-1} inited
2018-04-23 15:12:20.829 [main] INFO com.alibaba.druid.pool.DruidDataSource - {dataSource-2} inited
2018-04-23 15:12:21.099 [main] INFO com.taobao.yugong.controller.YuGongController - check source tables is ok.
2018-04-23 15:12:21.942 [main] INFO com.taobao.yugong.controller.YuGongController - ## prepare start tables[1] with concurrent[5]
2018-04-23 15:12:22.256 [main] INFO com.taobao.yugong.YuGongLauncher - ## the YuGong is running now ......
2018-04-23 15:12:22.260 [YuGongInstance-TEST.ORACLE1] INFO com.taobao.yugong.controller.YuGongInstance - table[TEST.ORACLE1] is start
2018-04-23 15:12:22.266 [main] INFO com.taobao.yugong.YuGongLauncher -
[YuGong Version Info]
[version ]
[hexVeision]
[date ]2016-06-08 17:51:04
[branch ](HEAD
[url ]git@github.com:alibaba/yugong.git
2018-04-23 15:13:21.945 [pool-2-thread-2] INFO com.taobao.yugong.common.stats.ProgressTracer - {未启动:0,全量中:0,增量中:0,已追上:1,异常数:0}
2018-04-23 15:13:21.945 [pool-2-thread-2] INFO com.taobao.yugong.common.stats.ProgressTracer - 已完成:[TEST.ORACLE1]
查看表同步日志
[root@www.cndba.cn TEST.ORACLE1]# cd /yugong/logs/TEST.ORACLE1
[root@www.cndba.cn TEST.ORACLE1]# tail -50f table.log
[root@www.cndba.cn TEST.ORACLE1]# more table.log
2018-04-23 15:12:22.459 [YuGongInstance-TEST.ORACLE1] INFO c.t.yugong.extractor.oracle.OracleAllRecordExtractor - table [TEST.ORACLE1] full extractor is end , next auto start inc extractor
2018-04-23 15:12:22.693 [YuGongInstance-TEST.ORACLE1] INFO c.t.y.e.oracle.OracleMaterializedIncRecordExtractor - table[TEST.ORACLE1] now is NO_UPDATE ...
出现了:
1.full extractor is end , next auto start inc extractor #代表全量迁移已完成,自动进入增量模式
2.now is NO_UPDATE #代表增量表暂时无日志
5.10 oracle上执行增量变更
在源库oracle上对源表进行增量变更
insert into oracle1 values(3,'test','test',88,188, NULL , NULL ,sysdate,sysdate);
查看表同步日志
2018-04-23 15:13:47.989 [YuGongInstance-TEST.ORACLE1] INFO c.t.y.e.oracle.OracleMaterializedIncRecordExtractor - table[TEST.ORACLE1] now is CATCH_UP ...
会瞬间出现now is CATCH_UP,代表刚完成处理了增量数据,并且当前没有新的增量.
5.11 查看mysq目标库数据
MariaDB [test]> select * from mysql1;
+----+------------------------------------------+--------+-------+--------+--------+---------------------+---------------------+---------------------+
| id | display_name | amount | score | text_b | text_c | gmt_create | gmt_modified | gmt_move |
+----+------------------------------------------+--------+-------+--------+--------+---------------------+---------------------+---------------------+
| 1 | ljh(agapple ) | 10.2 | 100 | NULL | NULL | 2018-04-23 15:11:58 | 2018-04-23 15:11:58 | 2018-04-23 15:12:22 |
| 2 | yugong(yugong ) | 16.88 | 2088 | NULL | NULL | 2018-04-23 15:11:58 | 2018-04-23 15:11:58 | 2018-04-23 15:12:22 |
| 3 | test(test ) | 88 | 188 | NULL | NULL | 2018-04-23 15:13:40 | 2018-04-23 15:13:40 | 2018-04-23 15:13:47 |
+----+------------------------------------------+--------+-------+--------+--------+---------------------+---------------------+---------------------+
5.12 关闭yugong进程
[root@www.cndba.cn bin]# cd /yugong/bin
[root@www.cndba.cn bin]# ./stop.sh
6切换流程
1.当任务处于追上状态时候,表示已经处于实时同步状态
2.后续通过源数据库进行停写,稍等1-2分钟后(保证延时的数据最终得到同步,此时源库和目标库当前数据是完全一致的)
3.检查增量持续处于NO_UPDATE状态,可关闭该迁移任务(sh stop.sh),即可发布新程序,使用新的数据库,完成切换的流程.
7日志说明
对应日志结构为:
logs/
- yugong/ #系统根日志
- table.log
- ${table}/ #每张同步表的日志信息
- table.log
- extractor.log
- applier.log
- check.log
全量完成的日志:(会在yugong/table.log 和 ${table}/table.log中出现记录)
table[OTTER2.TEST_ALL_ONE_PK] is end!
增量日志:(会在${table}/table.log中出现记录)
table[OTTER2.TEST_ALL_ONE_PK] now is CATCH_UP ... #代表已经追上,最后一次增量数据小于onceCrawNum数量
table[OTTER2.TEST_ALL_ONE_PK] now is NO_UPDATE ... #代表最近一次无增量数据
ALL(全量+增量)模式日志: (会在${table}/table.log中出现记录)
table [OTTER2.TEST_ALL_ONE_PK] full extractor is end , next auto start inc extractor #出现这条代表全量已经完成,进入增量模式
CHECK日志: (会在${table}/check.log中出现diff记录)
-----------------
- Schema: yugong , Table: test_all_one_pk
-----------------
---Pks
ColumnValue[column=ColumnMeta[index=0,name=ID,type=3],value=2576]
---diff
ColumnMeta[index=3,name=AMOUNT,type=3] , values : [0] vs [0.0]
同步过程数据日志:会通过extractor.log/applier.log分别记录extractor和applier的数据记录,因为有DataTranslator的存在,两者记录可能不一致,所以分开两份记录.
统计信息:
progress统计,会在主日志下,输出当前全量/增量/异常表的数据,可通过该日志,全局把握整个迁移任务的进度,输出类似:
{未启动:0,全量中:2,增量中:3,已追上:3,异常数:0}
stat统计,会在每个表迁移日志下,输出当前迁移的tps信息
{总记录数:180000,采样记录数:5000,同步TPS:4681,最长时间:215,最小时间:212,平均时间:213}
8运行模式详细介绍
8.1 MARK模式(MARK)
开启增量日志的记录,如果是oracle就是创建物化视图
8.2 CLEAR模式(CLEAR)
清理增量日志的记录,如果是oracle就是删除物化视图
8.3 全量模式(FULL)
全量模式,顾名思议即为对源表进行一次全量操作,遍历源表所有的数据后,插入目标表.
全量有两种处理方式:
1.分页处理:如果源表存在主键,只有一个主键字段,并且主键字段类型为Number类型,默认会选择该分页处理模式. 优点:支持断点续做,对源库压力相对较小。 缺点:迁移速度慢
2.once处理:通过select * from访问整个源表的某一个mvcc版本的数据,通过cursor.next遍历整个结果集. 优点:迁移速度快,为分页处理的5倍左右。 缺点:源库压力大,如果源库并发修改量大,会导致数据库MVCC版本过多,出现栈错误. 还有就是不支持断点续做.
特别注意
如果全量模式运行过程中,源库有变化时,不能保证源库最近变化的数据能同步到目标表,这时需要配合增量模式. 具体操作就是:在运行全量模式之前,先开启增量模式的记录日志功能,然后开启全量模式,完成后,再将最近变化的数据通过增量模式同步到目标表
8.4 增量模式(INC)
全量模式,顾名思议即为对源表增量变化的数据插入目标表,增量模式依赖记录日志功能.
目前增量模式的记录日志功能,是通过oracle的物化视图功能。
创建物化视图
CREATE MATERIALIZED VIEW LOG ON ${tableName} with primary key.
•运行增量模式之前,需要先开启记录日志的功能,即预先创建物化视图. 特别是配合全量模式时,创建物化视图的时间点要早于运行全量之前,这样才可以保证数据能全部同步到目标表
•增量模式没有完成的概念,它只有追上的概念,具体的停止需有业务进行判断,可以看一下切换流程
8.5 自动模式(ALL)
自动模式,是对全量+增量模式的一种组合,自动化运行,减少操作成本.
自动模式的内部实现步骤:
1.开启记录日志功能. (创建物化视图)
2.运行全量同步模式. (全量完成后,自动进入下一步)
3.运行增量同步模式. (增量模式,没有完成的概念,所以也就不会自动退出,需要业务判断是否可以退出,可以看一下切换流程)
8.6 对比模式(CHECK)
对比模式,即为对源库和目标库的数据进行一次全量对比,验证一下迁移结果. 对比模式为一种可选运行,做完全量/增量/自动模式后,可选择性的运行对比模式,来确保本次迁移的正确性.
9参考链接
https://github.com/alibaba/yugong/wiki/QuickStart
https://github.com/alibaba/yugong/wiki/AdminGuide
版权声明:本文为博主原创文章,未经博主允许不得转载。






