TiDB异步在线DDL变更流程原理简概
具体文章详述:
TiDB 的异步 schema 变更实现:http://zimulala.github.io/2016/02/02/schema-change-implement/
TiDB 的异步 schema 变更优化: http://zimulala.github.io/2017/12/24/optimize/
背景
现在一般数据库在进行 DDL 操作时都会锁表,导致线上对此表的 DML 操作全部进入等待状态(有些数据支持读操作,但是也以消耗大量内存为代价),即很多涉及此表的业务都处于阻塞状态,表越大,影响时间越久。这使得 DBA 在做此类操作前要做足准备,然后挑个天时地利人和的时间段执行。为此,架构师们在设计整个系统的时候都会很慎重的考虑表结构,希望将来不用再修改。但是未来的业务需求往往是不可预估的,所以 DDL 操作无法完全避免。由此可见原先的机制处理 DDL 操作是令许多人都头疼的事情。本文将会介绍 TiDB 是如何解决此问题的。
新概念:
- 元数据记录:为了简化设计,引入 system database 和 system table 来记录异步 schema 变更的过程中的一些元数据。
- State:根据 F1 的异步 schema 变更过程,中间引入了一些状态,这些状态要和 column,index, table 以及 database 绑定, state 主要包括 none, delete only, write only, write reorganization, public。前面的顺序是在创建操作的时候的,创建操作的状态与它d的顺序相反,write reorganization 改为 delete reorganization,虽然都是 reorganization 状态,但是由于可见级别是有很大区别的,所以将其分为两种状态标记。
- Lease:同一时刻系统所有节点中 schema 最多有两个不同的版本,即最多有两种不同状态。正因为如此,一个租期内每个正常的节点都会自动加载 schema 的信息,如果不能在租期内正常加载,此节点会自动退出整个系统。那么要确保整个系统的所有节点都已经从某个状态更新到下个状态需要 2 倍的租期时间。
- Job: 每个单独的 DDL 操作可看做一个 job。在一个 DDL 操作开始时,会将此操作封装成一个 job 并存放到 job queue,等此操作完成时,会将此 job 从 job queue 删除,并在存入 history job queue,便于查看历史 job。
- Worker:每个节点都有一个 worker 用来处理 job。
- Owner:整个系统只有一个节点的 worker 能当选 owner 角色,每个节点都可能当选这个角色,当选 owner 后 worker 才有处理 job 的权利。owner 这个角色是有任期的,owner 的信息会存储在 KV 层中。worker定期获取 KV 层中的 owner 信息,如果其中 ownerID 为空,或者当前的 owner 超过了任期,则 worker 可以尝试更新 KV 层中的 owner 信息(设置 ownerID 为自身的 workerID),如果更新成功,则该 worker 成为 owner。在租期内这个用来确保整个系统同一时间只有一个节点在处理 schema 变更。
- Background operations:主要用于 delete reorganization 的优化处理,跟前面的 worker 处理 job 机制很像。所以引入了 background job, background job queue, background job history queue, background worker 和 background owner,它们的功能跟上面提到的角色功能一一对应,这里就不作详细介绍。
DDL变更基本流程
本小节描述的是异步 DDL 变更的整体流程,忽略实现细节。假设系统中只有两个节点,TiDB Server 1 和 TiDB Server 2。其中 TiDB Server 1 是 DDL 操作的接收节点, TiDB Server 2 是 owner。如下图 2 展示的是在 TiDB Server 1 中涉及的流程,图 3 展示的是在 TiDB Server 2 中涉及的流程。
本小节描述的是异步 DDL 变更的整体流程,忽略实现细节。假设系统中只有两个节点,TiDB Server 1 和 TiDB Server 2。其中 TiDB Server 1 是 DDL 操作的接收节点, TiDB Server 2 是 owner。如下图 2 展示的是在 TiDB Server 1 中涉及的流程,图 3 展示的是在 TiDB Server 2 中涉及的流程。
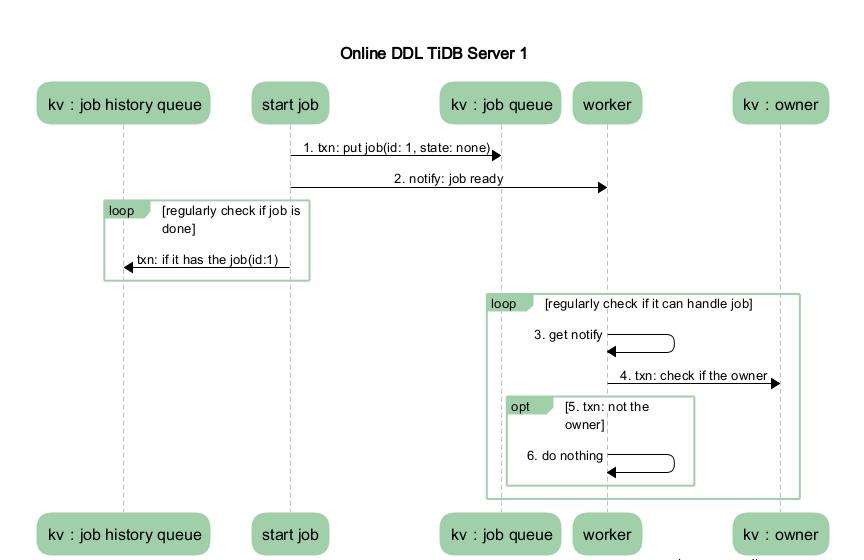
图 2 TiDB Server 1 流程图
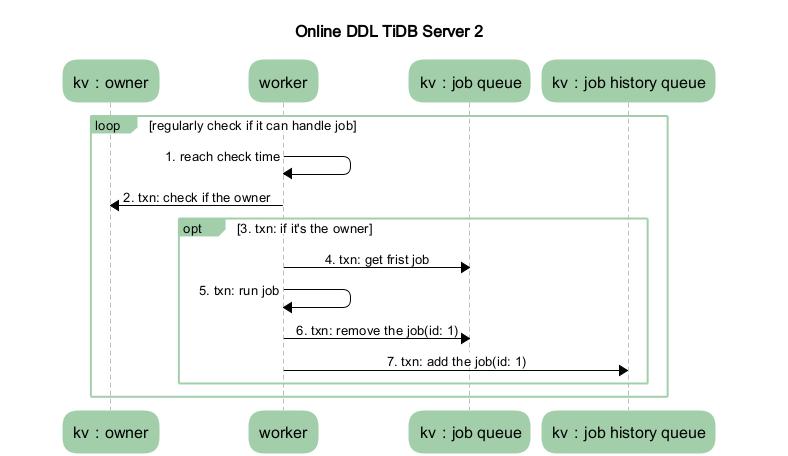
图 3 TiDB Server 2 流程图
- MySQL Client 发送给 TiDB Server 一个更改 DDL 的 SQL 语句请求。
- 某个 TiDB Server 收到请求(MySQL Protocol 层收到请求进行解析优化),然后到达 TiDB SQL 层进行执行。这步骤主要是在 TiDB SQL 层接到请求后,会起个 start job 的模块根据请求将其封装成特定的 DDL job,然后将此 job 存储到 KV 层, 并通知自己的 worker 有 job 可以执行。
- 收到请求的 TiDB Server 的 worker 接收到处理 job 的通知后,判断自身是否处于 owner 的角色,如果处于 owner 角色则直接处理此 job,如果没有处于此角色则退出不做任何处理。图中我们假设没有处于此角色,那么其他的某个 TiDB Server 中肯定有一个处于此角色的,如果那个处于 owner 角色节点的 worker 通过定期检测机制来检查是否有 job 可以被执行时(从整体角度上看,每个 DDL 操作的时间都是依赖 lease 的设置,每个状态变更需要 2 lease,那么每个 DDL 操作至少是 2 lease),发现了此 job,那么它就会处理这个 job。
- 当 worker 处理完 job 后, 它会将此 job 从 KV 层的 job queue 中移除,并放入 job history queue。
- 之前封装 job 的 start job 模块会定期去 job history queue 查看是否有之前放进去的 job 对应 ID 的 job,如果有则整个 DDL 操作结束。
- TiDB Server 将 response 返回 MySQL Client。
变更优化的内容
具体优化内容
将 owner 选举放在 PD 上处理,并用 PD 通知所有 TiDB DDL 状态变更的情况。前者可以略微减少 TiKV 压力,也解决用本地时间选取 owner 的隐患,后者可以减少每个 DDL 操作处理的等待时间。
Owner 选举
每个 DDL 对应一个竞选 owner 的 goroutine,它用来判断此 DDL 是否为 owner。也就是说与原来逻辑一样,每个 TiDB 的 DDL 知道自己是否为 owner,不知道其他 TiDB 的 owner 信息。 具体方法是用 PD 中内嵌的 etcd 接口,通过 Session 创建的 Election 调用 Campaign 接口进行 owner 选举。如果选举成功,那么将此 DDL 设置为 owner ,并监听这个 owner 对应的路径,那么当它不是 owner 时,可以收到通知,更新自己为非 owner 的信息。如果选举不成功,那么它为非 owner, 并一直排队,等到选举成功后做选举成功的流程。
drop 操作优化
对于原来 drop schema、drop table 和 drop index 等操作,在真正删除数据时,用 delete range 的方式替换原来放到后台处理的操作流程。 在前面举例的操作结束时,将对应的表信息和 range 信息(即数据的起始 key)记录到内部的特定表中。真正的清除数据的操作,是由 TiDB GC worker,在清理其他过期数据时同时清理。这个操作的优点,其一是把原来 background 部分的代码可以全部清理,不需要维护两部分类似代码;其二是它是直接调用 TiKV 的接口直接清理数据,不需要 TiDB 一批一批串行的清理数据,即方便又省各种资源。
Add Column 操作优化
这个优化效果会特别显著,因为实际上我们最后没有存那些数据。那么整个操作就不关心表的数据行数,整个操作只需要进行 5 个状态的变更即可。此操作前后做了两个优化: 新加列的 Default Value 是一个空值,那么就不需要实际的去填充。之后对此列的读取时,从 TiKV 返回的列值为空时,查看此列的元信息,如果它是 NULL 约束则可直接返回空值(这逻辑会在 Coprocess 处理)。 新加列的 Default Value 的值为非空的情况下,也不用将 Default Value 存储到 TiKV,只需将此默认值存到一个 schema 的字段(Original Default Value)中。在之后做读取操作时,如果发现 TiKV 返回此列的的值为空,且这个 schema 字段中的值为非空,那么将此字段中的值填充给这一列,然后返回(这逻辑会在 Coprocess 处理)。
Add Index 操作优化
原先 add index 最后填充数据就是通过批量处理。这样做是为了防止此操作的事务与其他在操作此 index 的事务发生冲突,导致整个 add index backfill 的操作重试从而进行分批处理。但是这个批量不是并发处理,只是为了减少冲突域做的。优化前串行逻辑是先扫一批 key,扫完之后对这批 key 的值进行修改。针对这个操作我们目前做了两次主要的优化。
第一次优化
此次优化主要分两部分:
- 减少对 TiKV 的访问,用 BatchGet 代替 Get,移除不必要的 Exist 的调用等。
- 对一些操作进行并发处理。此处的并发处理比一般的略微复杂,即真正的并发是在扫完一批 key 后对其进行的解析及真正修改 key 的值的处理。虽然每个 key 区间的长度可控, 但是这个区间的具体值由于一些删除操作不可预计, 所以需要串行地获取一批 key。这个优化用 go 处理还是特别方便易懂。通过一个小集群进行一定数量的对比测试后,请求执行时间大约是优化前的 ⅓ (具体需考虑表中数据行数,这些测试中表行数最少也是上万行)。其中并发个数是通过优化效果和冲突域两个参考值权衡下调整的。
第二次优化
此优化也分为两部分:
读写数据模式改为一次有多个 worker 并发的读写特定区域(handle range)数据,然后等待这次操作结束进行下一次操作。这个特定区域是用 handle 直接推测区间,那么可能会推测不准确,所以做了如下调整:
- 如果出现读的时候,读到的 handle 远大于此 worker 需要读 handle 区间的 end handle(说明此间有大批 handle 是无数据的),那么记录此 handle,更正下一次并发读时几个 worker 的 handle 区间,减少无用操作。
- 如果读取数据个数小于设定值,会动态调整 handle 区间。
在数据连续的情况下,能减少约 22% 的耗时(数据量在 1 亿行,4 个 TiKV,1 个 PD,2 TiDB)。但是 handle 可能被批量删除过或者插入时就是非常离散等原因,还是会使整个操作变慢,所以新的优化在计划中。
增加一些内存复用,从 profile 还是能看到有不少优化。
Show DDL jobs
希望查看当前 DDL 正在运行、等待运行以及已执行完成的 DDL job 时可以使用的语句。具体 SQL 语句如下:ADMIN SHOW DDL JOBS
Cancel DDL jobs
由于目前 DDL 操作都是串行执行的,操作人员由于手误或者手动重试,导致在一个大表上多次执行 add index 这种耗时比较久的操作,希望取消这个 DDL 语句的执行时,可以使用这个功能。具体 SQL 语句格式如下: ADMIN CANCEL DDL JOBS 'job_id' [, 'job_id'] ...
版权声明:本文为博主原创文章,未经博主允许不得转载。






